这里有最新的Python最常见的180道面试题解析。
当你发现这些题你差不多都能回答上来,那说明你的水平已经可以去面试工作了。
网上有网友搜集了 180 道最新的 Python 面试题解析,让你最短时间内掌握核心知识点,一举通过Python 面试!
1.列出 5 个常用 Python 标准库?
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
2.Python 内建数据类型有哪些?
1 | 整型--int |
3.简述 with 方法打开处理文件帮我我们做了什么?
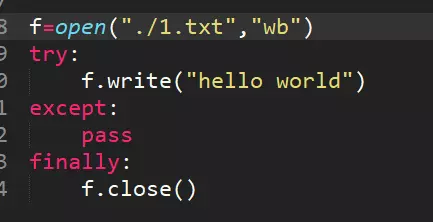
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
4.列出 Python 中可变数据类型和不可变数据类型,为什么?
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id
1 | a = 3 |
可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
1 | a = [1,2] |
5.Python 获取当前日期?
6.统计字符串每个单词出现的次数
7.用 python 删除文件和用 linux 命令删除文件方法
8.写一段自定义异常代码
1 | try: |
9.举例说明异常模块中 try except else finally 的相关意义
try..except..else没有捕获到异常,执行else语句
try..except..finally不管是否捕获到异常,都执行finally语句
10.遇到 bug 如何处理
语言特性
1.谈谈对 Python 和其他语言的区别
2.简述解释型和编译型编程语言
3.Python 的解释器种类以及相关特点?
4.说说你知道的Python3 和 Python2 之间的区别?
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print(‘hi’)
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print ‘hi’
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
5.Python3 和 Python2 中 int 和 long 区别?
6.xrange 和 range 的区别?
编码规范
7.什么是 PEP8?
8.了解 Python 之禅么?
9.了解 docstring 么?
10.了解类型注解么?
11.例举你知道 Python 对象的命名规范,例如方法或者类等
12.Python 中的注释有几种?
13.如何优雅的给一个函数加注释?
14.如何给变量加注释?
15.Python 代码缩进中是否支持 Tab 键和空格混用。
16.是否可以在一句 import 中导入多个库?
17.在给 Py 文件命名的时候需要注意什么?
18.例举几个规范 Python 代码风格的工具
数据类型
字符串
19.列举 Python 中的基本数据类型?
20.如何区别可变数据类型和不可变数据类型
21.将”hello world”转换为首字母大写”Hello World”
22.如何检测字符串中只含有数字?
23.将字符串”ilovechina”进行反转
24.Python 中的字符串格式化方式你知道哪些?
25.有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉。
26.获取字符串”123456“最后的两个字符。
27.一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作?
28. (1)s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong'](2) a = "你好 中国 ",去除多余空格只留一个空格。
29. (1)怎样将字符串转换为小写 (2)单引号、双引号、三引号的区别?
列表
30.已知 AList = [1,2,3,1,2],对 AList 列表元素去重,写出具体过程。
31.如何实现 “1,2,3” 变成 [“1”,”2”,”3”]
32.给定两个 list,A 和 B,找出相同元素和不同元素
33.[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
34.合并列表[1,5,7,9]和[2,2,6,8]
35.如何打乱一个列表的元素?
字典
36.字典操作中 del 和 pop 有什么区别
37.按照字典的内的年龄排序

38.请合并下面两个字典 a = {“A”:1,”B”:2},b = {“C”:3,”D”:4}
39.如何使用生成式的方式生成一个字典,写一段功能代码。
40.如何把元组(“a”,”b”)和元组(1,2),变为字典{“a”:1,”b”:2}
综合
41.Python 常用的数据结构的类型及其特性?

42.如何交换字典 {“A”:1,”B”:2}的键和值?
43.Python 里面如何实现 tuple 和 list 的转换?
44.我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
45.请将[i for i in range(3)]改成生成器
46.a=”hello”和 b=”你好”编码成 bytes 类型
1 | a="hello" |
输出:
1 | b'hello' b'\xe4\xb8\x96\xe7\x95\x8c' b'hello' |
47.下面的代码输出结果是什么?

48.下面的代码输出的结果是什么?

操作类题目
49.Python 交换两个变量的值
a = b
b = a
50.在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
51.json 序列化时,可以处理的数据类型有哪些?如何定制支持 datetime 类型?
52.json 序列化时,默认遇到中文会转换成 unicode,如果想要保留中文怎么办?
53.有两个磁盘文件 A 和 B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列),输出到一个新文件 C 中。
54.如果当前的日期为 20190530,要求写一个函数输出 N 天后的日期,(比如 N 为 2,则输出 20190601)。
55.写一个函数,接收整数参数 n,返回一个函数,函数的功能是把函数的参数和 n 相乘并把结果返回。
56.下面代码会存在什么问题,如何改进?

57.一行代码输出 1-100 之间的所有偶数。
58.with 语句的作用,写一段代码?
59.python 字典和 json 字符串相互转化方法
60.请写一个 Python 逻辑,计算一个文件中的大写字母数量
61. 请写一段 Python连接 Mongo 数据库,然后的查询代码。
62.说一说 Redis 的基本类型。
63. 请写一段 Python连接 Redis 数据库的代码。
1 | r = redis.Redis(host = 'localhost' ,post = 6379 ,db = 0) |
64. 请写一段 Python 连接 MySQL 数据库的代码。
1 | db = MySQLdb.connect("localhost","codecloud","test123","TESTDB" ) |
65.了解 Redis 的事务么?
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务的基础。
事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
EXEC 命令负责触发并执行事务中的所有命令:
当使用 AOF 方式做持久化的时候, Redis 会使用单个 write(2) 命令将事务写入到磁盘中。
然而,如果 Redis 服务器因为某些原因被管理员杀死,或者遇上某种硬件故障,那么可能只有部分事务命令会被成功写入到磁盘中。
如果 Redis 在重新启动时发现 AOF 文件出了这样的问题,那么它会退出,并汇报一个错误。
使用 redis-check-aof 程序可以修复这一问题:它会移除 AOF 文件中不完整事务的信息,确保服务器可以顺利启动。
- 如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。
- 另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
从 2.2 版本开始,Redis 还可以通过乐观锁(optimistic lock)实现 CAS (check-and-set)操作,具体信息请参考文档的后半部分。
用法:
MULTI 命令用于开启一个事务,它总是返回 OK 。
MULTI 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 EXEC 命令被调用时, 所有队列中的命令才会被执行。
另一方面, 通过调用 DISCARD , 客户端可以清空事务队列, 并放弃执行事务。
以下是一个事务例子, 它原子地增加了 foo 和 bar 两个键的值:
1 | > MULTI |
EXEC 命令的回复是一个数组, 数组中的每个元素都是执行事务中的命令所产生的回复。 其中, 回复元素的先后顺序和命令发送的先后顺序一致。
当客户端处于事务状态时, 所有传入的命令都会返回一个内容为 QUEUED 的状态回复(status reply), 这些被入队的命令将在 EXEC 命令被调用时执行。
事务中的错误:
使用事务时可能会遇上以下两种错误:
- 事务在执行 EXEC 之前,入队的命令可能会出错。比如说,命令可能会产生语法错误(参数数量错误,参数名错误,等等),或者其他更严重的错误,比如内存不足(如果服务器使用 maxmemory 设置了最大内存限制的话)。
- 命令可能在 EXEC 调用之后失败。举个例子,事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面,诸如此类。
对于发生在 EXEC 执行之前的错误,客户端以前的做法是检查命令入队所得的返回值:如果命令入队时返回 QUEUED ,那么入队成功;否则,就是入队失败。如果有命令在入队时失败,那么大部分客户端都会停止并取消这个事务。
不过,从 Redis 2.6.5 开始,服务器会对命令入队失败的情况进行记录,并在客户端调用 EXEC 命令时,拒绝执行并自动放弃这个事务。
在 Redis 2.6.5 以前, Redis 只执行事务中那些入队成功的命令,而忽略那些入队失败的命令。 而新的处理方式则使得在流水线(pipeline)中包含事务变得简单,因为发送事务和读取事务的回复都只需要和服务器进行一次通讯。
至于那些在 EXEC 命令执行之后所产生的错误, 并没有对它们进行特别处理: 即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会继续执行。
从协议的角度来看这个问题,会更容易理解一些。 以下例子中, LPOP 命令的执行将出错, 尽管调用它的语法是正确的:
1 | Trying 127.0.0.1... |
EXEC 返回两条批量回复(bulk reply): 第一条是 OK ,而第二条是 -ERR 。 至于怎样用合适的方法来表示事务中的错误, 则是由客户端自己决定的。
最重要的是记住这样一条, 即使事务中有某条/某些命令执行失败了, 事务队列中的其他命令仍然会继续执行 —— Redis 不会停止执行事务中的命令。
以下例子展示的是另一种情况, 当命令在入队时产生错误, 错误会立即被返回给客户端:
1 | MULTI |
因为调用 INCR 命令的参数格式不正确, 所以这个 INCR 命令入队失败。
为什么 Redis 不支持回滚(roll back)
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
鉴于没有任何机制能避免程序员自己造成的错误, 并且这类错误通常不会在生产环境中出现, 所以 Redis 选择了更简单、更快速的无回滚方式来处理事务。
放弃事务
当执行 DISCARD 命令时, 事务会被放弃, 事务队列会被清空, 并且客户端会从事务状态中退出:
1 | redis> SET foo 1OK redis> MULTIOK redis> INCR fooQUEUED redis> DISCARDOK redis> GET foo"1" |
使用 check-and-set 操作实现乐观锁
WATCH 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回空多条批量回复(null multi-bulk reply)来表示事务已经失败。
举个例子, 假设我们需要原子性地为某个值进行增 1 操作(假设 INCR 不存在)。
首先我们可能会这样做:
1 | val = GET mykeyval = val + 1SET mykey $val |
上面的这个实现在只有一个客户端的时候可以执行得很好。 但是, 当多个客户端同时对同一个键进行这样的操作时, 就会产生竞争条件。
举个例子, 如果客户端 A 和 B 都读取了键原来的值, 比如 10 , 那么两个客户端都会将键的值设为 11 , 但正确的结果应该是 12 才对。
有了 WATCH , 我们就可以轻松地解决这类问题了:
1 | WATCH mykey val = GET mykeyval = val + 1 MULTISET mykey $valEXEC |
使用上面的代码, 如果在 WATCH 执行之后, EXEC 执行之前, 有其他客户端修改了 mykey 的值, 那么当前客户端的事务就会失败。 程序需要做的, 就是不断重试这个操作, 直到没有发生碰撞为止。
这种形式的锁被称作乐观锁, 它是一种非常强大的锁机制。 并且因为大多数情况下, 不同的客户端会访问不同的键, 碰撞的情况一般都很少, 所以通常并不需要进行重试。
了解 WATCH
WATCH 使得 EXEC 命令需要有条件地执行: 事务只能在所有被监视键都没有被修改的前提下执行, 如果这个前提不能满足的话,事务就不会被执行。
如果你使用 WATCH 监视了一个带过期时间的键, 那么即使这个键过期了, 事务仍然可以正常执行, 关于这方面的详细情况,请看这个帖子: http://code.google.com/p/redis/issues/detail?id=270
WATCH 命令可以被调用多次。 对键的监视从 WATCH 执行之后开始生效, 直到调用 EXEC 为止。
用户还可以在单个 WATCH 命令中监视任意多个键, 就像这样:
1 | redis> WATCH key1 key2 key3OK |
当 EXEC 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。
另外, 当客户端断开连接时, 该客户端对键的监视也会被取消。
使用无参数的 UNWATCH 命令可以手动取消对所有键的监视。 对于一些需要改动多个键的事务, 有时候程序需要同时对多个键进行加锁, 然后检查这些键的当前值是否符合程序的要求。 当值达不到要求时, 就可以使用 UNWATCH 命令来取消目前对键的监视, 中途放弃这个事务, 并等待事务的下次尝试。
使用 WATCH 实现 ZPOP
WATCH 可以用于创建 Redis 没有内置的原子操作。
举个例子, 以下代码实现了原创的 ZPOP 命令, 它可以原子地弹出有序集合中分值(score)最小的元素:
1 | WATCH zsetelement = ZRANGE zset 0 0MULTI ZREM zset elementEXEC |
程序只要重复执行这段代码, 直到 EXEC 的返回值不是空多条回复(null multi-bulk reply)即可。
Redis 脚本和事务
从定义上来说, Redis 中的脚本本身就是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且一般来说, 使用脚本要来得更简单,并且速度更快。
因为脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了, 所以 Redis 才会同时存在两种处理事务的方法。
不过我们并不打算在短时间内就移除事务功能, 因为事务提供了一种即使不使用脚本, 也可以避免竞争条件的方法, 而且事务本身的实现并不复杂。
不过在不远的将来, 可能所有用户都会只使用脚本来实现事务也说不定。 如果真的发生这种情况的话, 那么我们将废弃并最终移除事务功能。
66.了解数据库的三范式么?
什么是范式:简言之就是,数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系。所以建立科学的,规范的的数据库是需要满足一些
规范的来优化数据数据存储方式。在关系型数据库中这些规范就可以称为范式。
什么是三大范式:
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要
求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF.
67.了解分布式锁么?
什么是锁
- 在单进程的系统中,当存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量。
- 而同步的本质是通过锁来实现的。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。
- 不同地方实现锁的方式也不一样,只要能满足所有线程都能看得到标记即可。如java中synchronize是在对象头设置标记,Lock接口的实现类基本上都只是某一个volitile修饰的int型变量其保证灭个线程都能拥有对该int的可见性和原子修改,linux内核中也是利用互斥量或信号量等内存数据做标记。
- 除了利用内存数据做锁其实任何互斥的都能做锁(只考虑互斥情况),如流水表中流水号与时间结合做幂等校验可以看作是一个不会释放的锁,或者使用某个文件是否存在作为锁等。只需要满足在对标记进行修改能保证原子性和内存可见性即可。
分布式
分布式情况
此处主要指集群模式下,多个相同服务同时开启.
- 分布式与单机情况下最大的不同在于其不是多线程而是多进程。
- 多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置。而进程之间甚至可能都不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
分布式锁
- 当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 与单机模式下的锁不仅需要保证进程可见,还需要考虑进程与锁之间的网络问题。(我觉得分布式情况下之所以问题变得复杂,主要就是需要考虑到网络的延时和不可靠。。。一个大坑)
- 分布式锁还是可以将标记存在内存,只是该内存不是某个进程分配的内存而是公共内存如Redis、Memcache。至于利用数据库、文件等做锁与单机的实现是一样的,只要保证标记能互斥就行。
单机Redis锁
基本锁
- 原理:利用Redis的setnx如果不存在某个key则设置值,设置成功则表示取得锁成功。
- 缺点:如果获取锁后的进程,在还没执行完的时候挂调了,则锁永远不会释放。
改进型
- 改进:在基本型是锁上的setnx后设置expire,保证即使获取锁的进程不主动释放锁,过一段时间后也能自动释放。
- 缺点:
- setnx与expire不是一个原子操作,可能执行完setnx该进程就挂了。
- 当锁过期后,该进程还没执行完,可能造成同时多个进程取得锁。(貌似这个问题目前还没有很优雅的解决方案)
再改进
- 改进:利用Lua脚本,将setnx与expire变成一个原子操作,可解决一部分问题。
- 缺点:还是锁过期的问题。
步骤
1 | 1. 直接调用Lua脚本原子setnx同时expire,设置一个随机值。 |
总结
一般情况下直接用setnx加expire就够了,但从安全性的角度看还是存在一下几个问题:
- 单点问题。单机Redis只在单机上,如果单机down了,那么所有需要用分布式锁的地方均获取不到锁,全部阻塞。需要做好降级的处理。
- 可能出现多进程同时拥有锁。
Redlock
Redlock是Redis的作者antirez给出的集群模式的Redis分布式锁,它基于N个完全独立的Redis节点(通常情况下N可以设置成5)。
步骤
1 | 1. 获取当前时间(毫秒数)。 |
优化
- 当有5个节点,某次上锁对a,b,c三个节点上锁成功,而后c马上down了,此时还没通过AOF或RDB写入磁盘。而后c又马上恢复,此时c没有上锁数据,因此此时可能出现c,d,e三个节点被别的进程上锁。所以在节点恢复时应该延时起码一个锁的过期时间。
Zookeeper锁
zookeeper锁相关基础知识
- zk一般由多个节点构成(单数),采用zab一致性协议。因此可以将zk看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
- zk的数据以目录树的形式,每个目录称为 znode, znode中可存储数据(一般不超过1M),还可以在其中增加子节点。
- 子节点有三种类型。序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。最后就是普通节点。
- Watch机制,client可以监控每个节点的变化,当产生变化会给client产生一个事件。
zk基本锁
- 原理:利用临时节点与watch机制。每个锁占用一个普通节点/lock,当需要获取锁时在/lock下创建一个临时节点,创建成功则表示获取锁成功,失败则watch/lock节点,有删除操作后再去争锁。临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁。
- 缺点:所有取锁失败的进程都监听父节点,很容易发生羊群效应,即当释放锁后所有等待进程一起来创建节点,并发量很大。
zk锁 优化
- 原理:上锁改为创建临时有序节点,每个上锁的节点均能创建节点成功,知识其序号不同。只有序号最小的可以拥有锁,当需要不是最小的则watch序号排在前面的一个节点(公平锁)。
- 步骤:
1 | 1. 在/lock节点下创建一个有序临时节点(EPHEMERAL_SEQUENTIAL)。 |
分布式锁总结
分布式锁存在的问题
- 均可能存在多进程拥有锁的情况。redis锁主要是expire时间与代码执行时间的问题,zk锁的问题在于zk是通过心跳监控进程存活状态,如果进程进行GC pause或者因为网络原因导致很长时间没与zk联系,则将导致zk认为进程已挂,而后锁自动释放,而此时进程并未挂任然在执行。
- Redlock锁的时间问题。由于redis的expire的实现是通过pexpireat,如果某个节点发生时钟跳跃,则该节点可能过早释放锁导致一系列问题。
解决方案
- 获取锁时提供一个fencing token(两种说法,一种说需要有序,一种说随机值就可以,我觉得随机值就可以),在进程获取锁后对数据进行操作时,数据所在的资源服务器需要去锁中查看当前token,如果token对的才执行,不对则放弃执行。
- 我觉得对于放弃执行的应该在我们的代码块中增加类似事物的rollback的操作。因此如果资源服务器拒绝了我们的操作则表明此时起码已经存在了另外一个进程拥有锁了,为了保证数据安全性不能继续执行,因此需要回滚到执行代码块之前而继续去竞争锁。
- 至于Redis锁的时间问题,Antirez说在运维层面是可以控制时钟跳跃的区间的,只要能控制跳跃区间与expire的比例就没问题,详细可看《基于Redis的分布式锁真的安全吗?》
总结
- 大多数时候采用zk锁就好了,没必要再考虑安全性的问题。其实也可以通过zk锁+幂等校验来达到双层保障。
- fencing 机制需要对数据服务进行修改适配,个人觉得没这个必要吧。。。
目前就这些了。。。。后面想到再补充吧。
68.用 Python 实现一个 Reids 的分布式锁的功能。
用 Python 实现一个 Reids 的分布式锁的功能
1 | SETNX lock.foo <current Unix time + lock timeout + 1> |
如果 SETNX 返回1,说明该进程获得锁,SETNX将键 lock.foo 的值设置为锁的超时时间(当前时间 + 锁的有效时间)。 如果 SETNX 返回0,说明其他进程已经获得了锁,进程不能进入临界区。进程可以在一个循环中不断地尝试 SETNX 操作,以获得锁。
1 | import time |
69.写一段 Python 使用 Mongo 数据库创建索引的代码。
初始话链接
1 | import pymongo |
创建表并初始话索引
如果不指定索引名称,默认使用index语句为索引名称,如果索引过长会报
1 | pymongo.errors.OperationFailure: exception: namespace name generated from index name "test.table01.${"imei":1,"vin":1,"startTime":1,"startTime":-1,"endTime":1,"endTime":-1,"channelld":1,"status":1}_1" is too long (127 byte max) |
脚本
1 | table01= mydb["table01"] |
高级特性
70.函数装饰器有什么作用?请列举说明?
71.Python 垃圾回收机制?
72.魔法函数 call怎么使用?
73.如何判断一个对象是函数还是方法?
74.@classmethod 和@staticmethod 用法和区别
75.Python 中的接口如何实现?
76.Python 中的反射了解么?
77.metaclass 作用?以及应用场景?
78.hasattr() getattr() setattr()的用法
79.请列举你知道的 Python 的魔法方法及用途。
80.如何知道一个 Python 对象的类型?
81.Python 的传参是传值还是传址?
82.Python 中的元类(metaclass)使用举例
83.简述 any()和 all()方法
84.filter 方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
85.什么是猴子补丁?
86.在 Python 中是如何管理内存的?
87.当退出 Python 时是否释放所有内存分配?
正则表达式
88.使用正则表达式匹配出<html><h1>[百度一下,你就知道](https://link.zhihu.com/?target=http%3A//www.baidu.com)</html>中的地址 a=”张明 98 分”,用 re.sub,将 98 替换为 100
89.正则表达式匹配中(.)和(.?)匹配区别?
90.写一段匹配邮箱的正则表达式
其他内容
91.解释一下 python 中 pass 语句的作用?
92.简述你对 input()函数的理解
93.python 中的 is 和==
94.Python 中的作用域
95.三元运算写法和应用场景?
96.了解 enumerate 么?
97.列举 5 个 Python 中的标准模块
98.如何在函数中设置一个全局变量
99.pathlib 的用法举例
100.Python 中的异常处理,写一个简单的应用场景
101.Python 中递归的最大次数,那如何突破呢?
102.什么是面向对象的 mro
103.isinstance 作用以及应用场景?
104.什么是断言?应用场景?
105.lambda 表达式格式以及应用场景?
106.新式类和旧式类的区别
107.dir()是干什么用的?
108.一个包里有三个模块,demo1.py, demo2.py, demo3.py,但使用 from tools import *导入模块时,如何保证只有 demo1、demo3 被导入了。
109.列举 5 个 Python 中的异常类型以及其含义
110.copy 和 deepcopy 的区别是什么?
111.代码中经常遇到的args, *kwargs 含义及用法。
112.Python 中会有函数或成员变量包含单下划线前缀和结尾,和双下划线前缀结尾,区别是什么?
113.w、a+、wb 文件写入模式的区别
114.举例 sort 和 sorted 的区别
115.什么是负索引?
116.pprint 模块是干什么的?
117.解释一下 Python 中的赋值运算符
118.解释一下 Python 中的逻辑运算符
119.讲讲 Python 中的位运算符
120.在 Python 中如何使用多进制数字?
121.怎样声明多个变量并赋值?
算法和数据结构
122.已知:
