什么是scrapy_redis?**
基于redis组件。
为什么要学习scrapy_redis?
scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:request去重,爬虫持久化,和轻松实现分布式
- 去重:不单单是当前的去重,而且是我们只要是部分文件存在,可以达到持久化去重,第二次运行不会抓取第一次运行爬取过得url地址。
- 增量式爬虫:爬过的地址不在爬取。
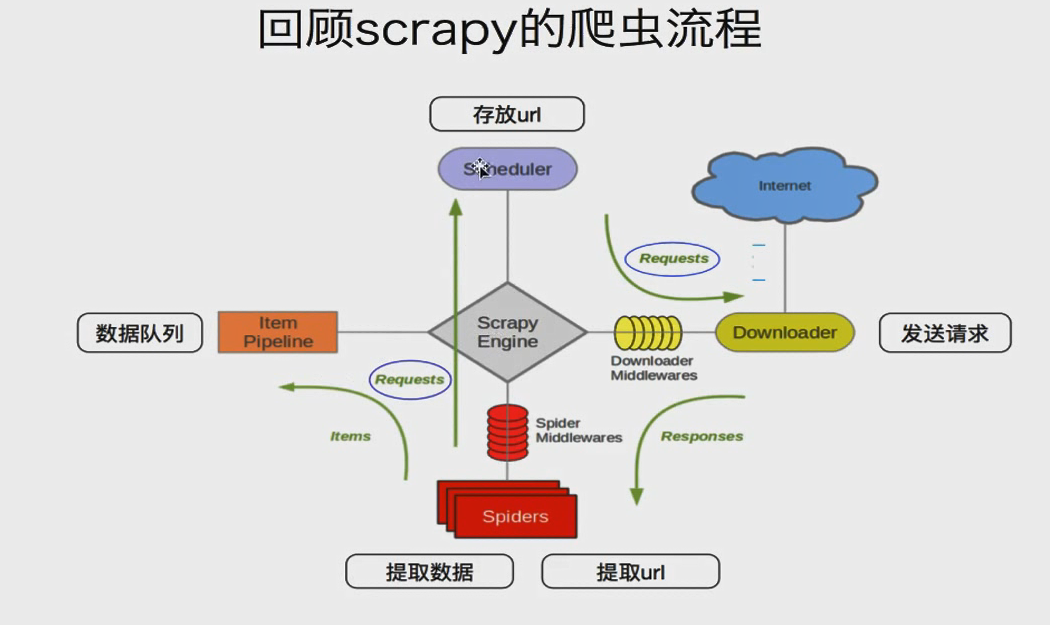
回顾scrapy的爬虫流程:
Scrapy_redis流程:
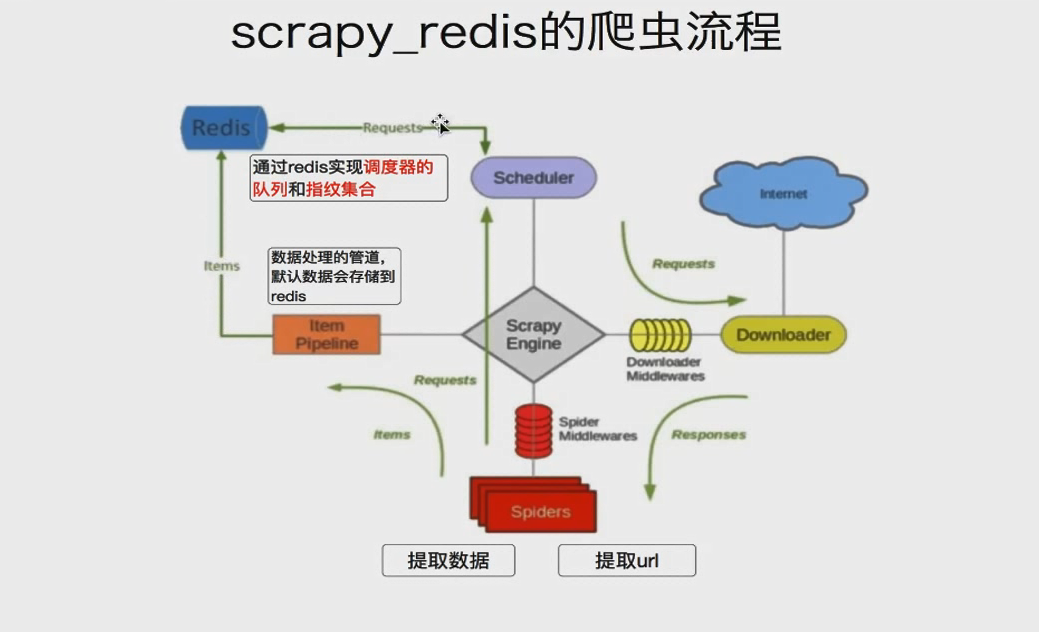
如果有多台电脑公用一个redis,
scrapy抓取过的url就不会再抓了,
存入url地址之间会做一个去重,他是给每个request对象生成一个指纹(唯一标记request对象)。